회사 문서를 외부 AI에 넣어도 괜찮을지 망설여본 적 있다면, 그 불안이 지금 국가 단위로 번지고 있다는 걸 알 필요가 있습니다.
2026년의 AI 경쟁은 더 이상 "누가 더 똑똑한 모델을 만드느냐"만의 싸움이 아닙니다. 어떤 데이터로, 어떤 인프라 위에서, 누구의 통제 아래 AI를 운영하느냐가 핵심이 됐습니다. 소버린 AI란 자국의 데이터, 기술, 인프라를 기반으로 AI 시스템을 독자적으로 개발·운영하는 전략을 뜻하며, 그 목적은 해외 기술 의존을 낮추고 데이터 주권과 국가 이익을 지키는 데 있습니다.

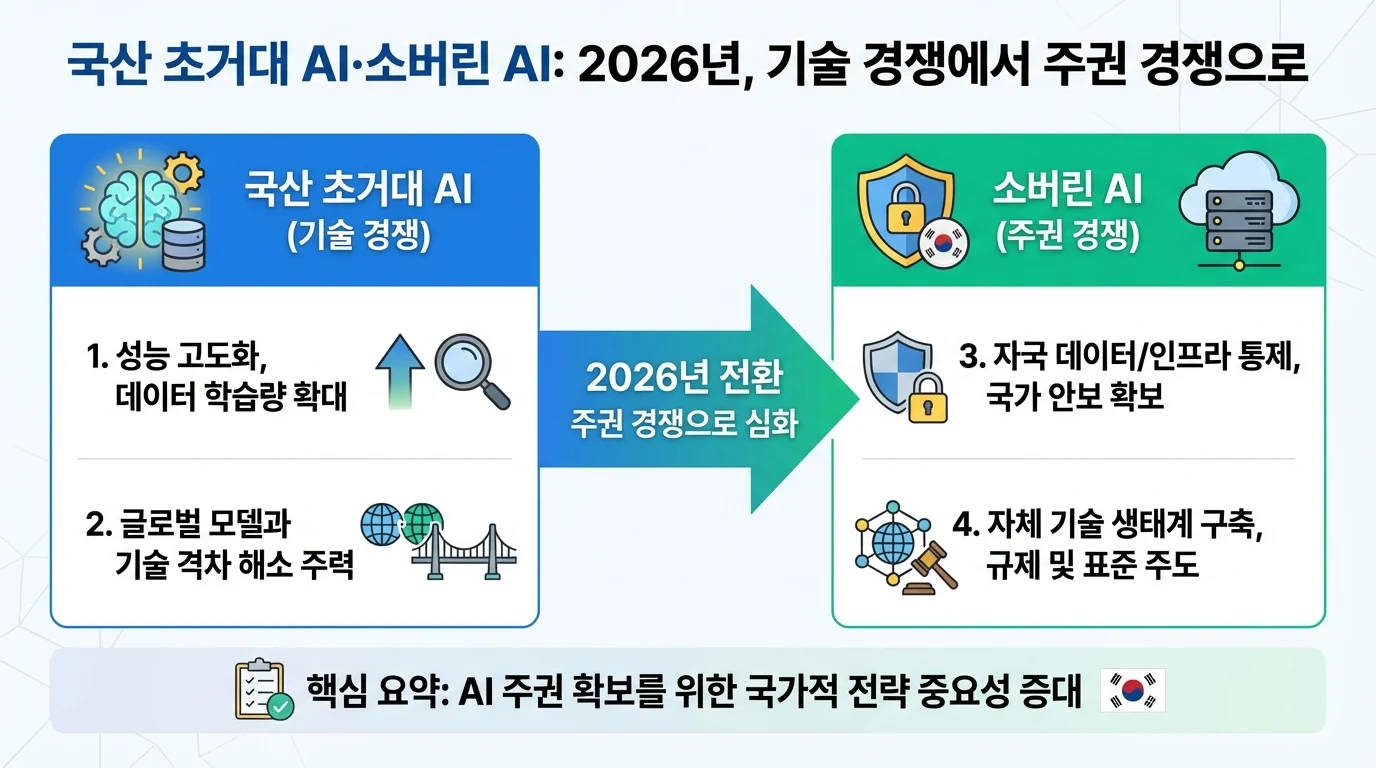
두 개념이 왜 항상 함께 나오는가
국산 초거대 AI와 소버린 AI는 비슷해 보이지만 강조점이 다릅니다.
초거대 AI는 대규모 데이터와 컴퓨팅 자원을 바탕으로 학습된 대형 인공지능 모델입니다. GPT-4나 네이버의 하이퍼클로바 X처럼 언어 이해부터 코드 작성까지 광범위한 작업을 처리할 수 있습니다. 소버린 AI는 모델의 크기보다 통제권에 무게를 둡니다. 데이터가 어디에 저장되는지, 학습과 운영 주체는 누구인지, 인프라를 누가 관리하는지가 핵심입니다.
단순하게 정리하면: 초거대 AI가 "엔진"이라면, 소버린 AI는 "그 엔진을 누구 차고에 두고 누가 키를 쥐는가"의 문제입니다.
한국이 국산 모델을 이야기할 때 자연스럽게 소버린 AI 전략으로 이어지는 이유가 여기에 있습니다. 금융, 의료, 공공, 국방처럼 민감한 영역일수록 외국 모델 의존이 커지면 데이터 유출 위험, 기술 종속, 안보 리스크도 함께 커질 수 있습니다.
한국 기업이 만드는 AI: 성능보다 '맥락'
국산 모델의 의미는 "한국 기업이 만들었다"에서 끝나지 않습니다. 한국어 이해, 국내 산업 맥락, 민감 데이터 처리 환경, 기업 시스템과의 연결성까지 묶여야 실제 경쟁력이 됩니다.
네이버의 하이퍼클로바 X는 방대한 한국어 데이터를 바탕으로 개발돼 검색·커머스·클라우드 서비스에 직접 적용되고 있습니다. 한국어 최적화가 단순한 편의 기능처럼 보이지만, 업무 정확도와 서비스 품질을 결정짓는 핵심 요소입니다.
KT는 통신 데이터를 포함한 자체 데이터로 초거대 AI '믿음(Mi:dm)'을 개발해 금융·의료·교육 등 산업별 B2B 시장에 AIaaS 형태로 제공하고 있습니다. 눈여겨볼 지점은 방향성입니다. "범용 챗봇"이 아니라 "산업 현장에 바로 얹는 AI"로 무게중심이 이동하고 있습니다.
LG의 엑사원도 같은 흐름입니다. 제조, 화학, 바이오 같은 핵심 산업에서 연구와 문제 해결에 활용하는 방향으로 확대되고 있으며, 소비자용 화제성보다 산업 문제를 실제로 푸는 쪽에서 존재감을 키우고 있습니다.
국내 클라우드 기업들의 데이터센터 투자와 보안 강화까지 더하면, 소버린 AI는 특정 모델 하나의 이름이 아니라 생태계 전체의 문제라는 그림이 선명해집니다.
해외는 이미 '주권'을 제도로 굳히고 있다
유럽은 규칙부터 세웠습니다. EU의 AI Act는 AI 시스템의 안전성, 투명성, 신뢰성을 법으로 규정하고 시민 데이터 보호와 역내 AI 기술 독립성을 명문화했습니다. "좋은 모델"보다 "믿고 쓸 수 있는 체계"를 먼저 구축하는 방식입니다.
미국은 다른 경로를 택했습니다. 민간 주도 혁신을 유지하면서도 국가 안보와 인재 양성에 집중 투자해 글로벌 AI 리더십을 지키려는 전략입니다. 시장 속도와 국가 전략을 동시에 가져가는 구조입니다.
중국은 국가 주도 방식이 더 강합니다. 막대한 자원과 데이터를 자국 기업 중심 생태계로 집중시키고 데이터 통제를 강화하며 AI를 국가 전략의 핵심 축으로 삼고 있습니다.
방향은 달라도 공통점은 하나입니다. 주요국 모두 AI를 단순한 산업 기술이 아니라 주권, 안보, 경제의 문제로 다루고 있습니다. 한국도 "잘 쓸 수 있는 모델 하나"가 아니라 "지속 가능한 자국 AI 체계"를 설계해야 하는 이유입니다.
이 흐름이 실제로 중요해지는 순간
기업 입장에서 AI 도입 질문이 달라지고 있습니다. "어떤 AI가 더 잘 쓰나?"에서 "우리 데이터 환경에 맞나, 국내 규제를 감당할 수 있나, 장기적으로 기술 종속 위험은 없나"로 이동 중입니다.
정책 입안자에게 국산 AI 육성은 산업 지원만의 문제가 아닙니다. 데이터, 클라우드, 보안, 규제, 인재가 함께 묶여야 소버린 AI가 실제로 작동합니다. 생태계 설계 없이 모델만 키우는 것은 반쪽짜리 전략입니다.
일반 사용자에게도 이 흐름은 점점 가까워집니다. 검색, 업무 도구, 교육, 의료 상담, 금융 서비스까지 AI가 깊숙이 들어올수록, 어느 나라 기준과 인프라 위에서 돌아가는 AI인지가 서비스 신뢰와 품질에 직접 연결됩니다.
과장 없이 봐야 할 현실
국산 초거대 AI·소버린 AI가 중요하다는 말이 곧 모든 영역에서 외산 모델을 즉시 교체한다는 뜻은 아닙니다.
균형도 중요합니다. 소버린 AI가 폐쇄성이나 비효율로 흘러가면 경쟁력을 잃고, 반대로 외부 기술에만 기대면 편의는 얻어도 통제권을 잃습니다. 자립과 협력의 균형을 어디에 놓을 것인가가 핵심이며, 2026년 한국 AI 전략은 바로 그 지점에서 평가받게 됩니다.
결론
국산 초거대 AI·소버린 AI는 기술 유행어가 아닙니다. 내 데이터가 어디로 가는지, 우리 산업이 누구 기술에 기대는지, 한국이 AI 시대에 어떤 협상력을 갖는지를 묻는 현실적인 질문입니다.
2026년의 경쟁에서 중요한 기준은 하나입니다. 성능이 좋아 보이는가보다, 우리 언어와 산업에 맞고 우리 통제 아래에서 오래 운영할 수 있는가. 이 질문에 제대로 답할 수 있는 쪽이 앞서갑니다.


